Python – Module re
import re will help you to use regular expression inside Python.
“Regular expressions are huge time-savers […]. Knowing them can mean the difference between solving a problem in 3 steps and solving it in 3,000 steps”.
Al Sweigart | https://automatetheboringstuff.com/2e/chapter7/
Regex helps you to find text patterns in a text without coding the pattern recognition itself in Python.
re.search(pattern,string)
This function returns a Match Object. Match objects always have a boolean value of True. match() and search() return None when there is no match.
It will return the first match only.
If you have multiple match, it’s better to use findall()
import re
pattern = r'\d\d-\d\d-\d\d-\d\d-\d\d'
mytext = 'My phone number is 01-23-45-67-89.'
mo = re.search(pattern,mytext)
print(mo)
print('The phone number is: ' + mo.group())
<re.Match object; span=(19, 33), match='01-23-45-67-89'>
The phone number is: 01-23-45-67-89“The compiled versions of the most recent patterns passed to re.match(), re.search() or re.compile() are cached, so programs that use only a few regular expressions at a time needn’t worry about compiling regular expressions.”[1]
In other cases just feed search(), findall() with re.compile(r'pattern') see compile under.
re.group()
If you use match() or search(), you will need this to show the result.
If you use () in some part of your pattern you can create subgroups.
The first group will have the id 1.
(group(0) or group() will return the complete match)
import re
# group(1) group(2)
# || ||
# \/ \/
pattern = r'(\d\d)-(\d\d-\d\d-\d\d-\d\d)'
mytext = 'My phone number is 01-23-45-67-89.'
mo = re.search(pattern,mytext)
print(mo.group(1))
print(mo.group(2))
print(mo.group(0))
print('The phone number is: ' + mo.group())
01
23-45-67-89
01-23-45-67-89
The phone number is: 01-23-45-67-89re.compile(pattern)
If you think that you will use a lot of regex in your scripts, it could be better to compile it. To help you decide, make the comparison in command line and use python -m timeit -s with your code or see this page.
- python -m timeit -s “import re” “pattern = r'(\d\d)-(\d\d-\d\d-\d\d-\d\d)'” “mytext = ‘My phone number is 01-23-45-67-89.'” “mo = re.search(pattern,mytext)” “print(mo.group(1))” “print(mo.group(2))” “print(mo.group(0))” “print(‘The phone number is: ‘ + mo.group())”
- python -m timeit -s “import re” “pattern = r'(\d\d)-(\d\d-\d\d-\d\d-\d\d)'” “phoneNumRegex = re.compile(pattern)” “mytext = ‘My phone number is 01-23-45-67-89.'” “mo = phoneNumRegex.search(mytext)” “print(mo.group(1))” “print(mo.group(2))” “print(mo.group(0))” “print(‘The phone number is: ‘ + mo.group())”
If you just put the regex part (without print in my example) you may see an insignificant difference. In my case I have 1,62 µsec (per loop) noncompiled vs 1,69 µsec (per loop) compiled.
But if I put my complete code, I have 3,35 ms (per loop) for the noncompiled version of the regex vs 2,26 ms (per loop) when it’s compiled. It’s 32% faster compiled!
Another good reason to use the re.compile() is that you can add different keywords to simplify your patterns:
- re.IGNORECASE or re.I: to not specify explicitly upper/lower case in your pattern
- re.DOTALL or re.S: to allow to match any character event line return!
- re.VERBOSE or re.X: will ignore line return and you can comment each lines
- you can use | if you need to use more than one at the same time (like re.compile(‘pattern’, re.X|re.I|re.S)
import re
pattern = r'\d\d-\d\d-\d\d-\d\d-\d\d'
phoneRegex = re.compile(pattern)
mytext = 'My phone number is 01-23-45-67-89.'
mo = phoneRegex.search(mytext)
print(mo)
print('The phone number is: ' + mo.group())
<re.Match object; span=(19, 33), match='01-23-45-67-89'>
The phone number is: 01-23-45-67-89re.findall(pattern,string)
If it finds the pattern in the string, it will simply return a list with all the elements. In case you are using groups in your regex with (), the function will return a list of tuples with the different groups. You can also put () around the complete pattern to include the complete string searched
import re pattern = r'(\d\d)-(\d\d-\d\d-\d\d-\d\d)' phoneNumRegex = re.compile(pattern) mystring = 'Cell: 06-12-34-56-78 Work: 04-12-34-56-78' result = phoneNumRegex.findall(mystring) print(result)
[('06', '12-34-56-78'), ('04', '12-34-56-78')]Operators
| ^The | matches any string that starts with The |
| end$ | matches a string that ends with end |
| ^The end$ | exact string match (starts and ends with The end) |
| abc | matches any string that has the text abc in it |
| abc* | matches a string that has ab followed by 0 OR more c |
| abc+ | matches a string that has ab followed by 1 OR more c |
| abc? | matches a string that has ab followed by 0 OR 1 c |
| abc{2} | matches a string that has ab followed by 2 c |
| abc{2,} | matches a string that has ab followed by 2 or more c |
| abc{2,5} | matches a string that has ab followed by 2 up to 5 c |
| a(bc)* | matches a string that has a followed by zero or more copies of the sequence bc |
| a(bc){2,5} | matches a string that has a followed by 2 up to 5 copies of the sequence bc |
| a(b|c) | matches a string that has a followed by b or c (and captures b or c) |
| a[bc] | same as previous, but without capturing b or c |
More available here: https://www.rexegg.com/regex-quickstart.html
Examples of Patterns (following batman example on https://automatetheboringstuff.com/2e/chapter7/):

Greedy vs non-greedy
By default regex is greedy and will return the maximum length of a match. But If you add a ? after {} it will return the smallest match.
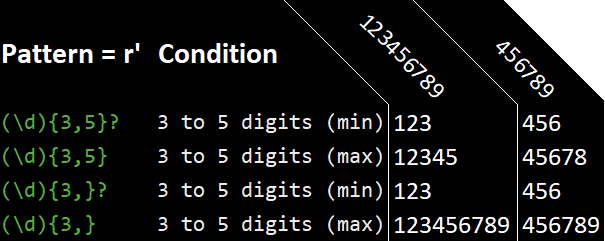
Characters classes
| \d | matches any digit from 0 to 9 |
| \D | matches any character that IS NOT a numeric digit from 0 to 9. |
| \w | matches a letter, numeric digit, or the underscore character. |
| \W | matches any character that IS NOT a letter, numeric digit, or the underscore character. |
| \s | matches any space, tab, or newline character |
| \S | matches any character that IS NOT space, tab, or newline character |
| . | matches any character (except new line) [<!> Use re.compile(pattern, re.DOTALL) to match any character] |

\w for word
\s for space
Combine with ./+/*or?, it can easily help to find strings after the string searched
import re
namesRegex = re.compile(r'Colonel \w+')
names = namesRegex.findall("Colonel Klink gave by mistake his document to Colonel Hogan.")
print(names)
['Colonel Klink', 'Colonel Hogan']Escape Characters
| \( or \) | to match ( or ) inside a text and do not interpret them as regex |
| \* \? \+ | to match * or ? or + inside a text and do not interpret them as regex |
Custom Character classes
| [abc] | matches a string that has either an a or a b or a c → it is the same as a|b|c |
| [a-c] | same as previous |
| [^abc] | matches a string that has not a letter from a to c. In this case the ^ is used as negation of the expression |
| [a-fA-F0-9] | a string that represents a single hexadecimal digit, case insensitively |
| [0-9]% | a string that has a character from 0 to 9 before a % sign |
You can use also use re.compile(r'[aeiou]’, re.I] to ignore the sensitive case of your pattern
Dot-Star tip
Sometimes you will want to match everything and anything. A super handy solution is to combine . and * → the dot-star.
For example, say you want to match a string you don’t know the length after ‘First Name:’ and the strings continue after with ‘Last Name:’ and another unknown size’s string.
r’First Name: (.*) Last Name: (.*)’ means that for each pattern having ‘First Name: xxxx Last Name: yyyy ‘ put in one group all characters coming after ‘First Name: ‘ until it encounters ‘ Last Name: ‘ and get all characters coming after it in a second group
The dot-star means that it will get any character for an unknown length (0 to infinite) after he found the pattern
import re
nameRegex = re.compile(r'First Name: (.*) Last Name: (.*)')
print(nameRegex.findall('First Name: José René Last Name: Hilton'))
[('José René, 'Hilton')]Even if it’s blank it will work (as we said 0 to infinite with *). If we want 1 or more, we can use .+
import re
nameRegex = re.compile(r'First Name: (.+) Last Name: (.+)')
print(nameRegex.search('First Name: Last Name: '))
print(nameRegex.search('First Name: Last Name: '))
<re.Match object; span=(0, 26), match='First Name: Last Name: '>
NoneSubstituting Strings with the sub() Method
Function to replace the string searched by another string. You can use \1 \2 \3 \n to get the value stored in the groups you defined in the pattern.
In the case under, we were searching for Colonel, Sergeant or Captain, it’s a dynamic value hence we cannot put it manually in the string we want to replace. We put this in group(1) and recall the value with \1. Group 2 is defined by the first letter of the name and we manually add***** to it
import re namesRegex = re.compile(r'(Colonel|Sergeant|Captain) (\w)\'*\w*') names = namesRegex.sub(r'\1 \2*****',"Colonel O'Neill gave the secret documents to Captain Carter.") print(names)
Colonel O***** gave the secret documents to Captain C*****.re.VERBOSE or re.X
Use in re.compile(pattern, re.X) helps you to comment your pattern. You will need triple quote to do this. The example under will give the same result than the one above
import re namesRegex = re.compile(r''' (Colonel|Sergeant|Captain) #Check if it encounters a military rank \s #separate by a space (\w) #take the first letter of the name of the military #and put it group(1) \'* #check if there is ' to not hide only the ' and #let the end of the name clear \w* #hide the name''' , re.VERBOSE) names = namesRegex.sub(r'\1 \2*****',"Colonel O'Neill gave the secret documents to Captain Carter.") print(names)
Colonel O***** gave the secret documents to Captain C*****.